Xiaomi Releases MiMo-V2.5-Pro and MiMo-V2.5: Frontier Model Benchmarks at Significantly Low Token Costs

The Xiaomi MiMo team has publicly released two new models: MiMo-V2.5-Pro again MiMo-V2.5. The benchmarks, combined with impressive real-world performance demos, make a compelling case that open agent AI is reaching the frontier sooner than expected. Both models are readily available via API, and are competitively priced.
What Is the Agentic Model, and Why Is It Important?
Most LLM benchmarks test a model’s ability to answer a single, self-contained question. Agency benchmarks test something very difficult — whether a model can complete a multi-step goal automatically, tools (web search, code execution, file I/O, API calls) are used multiple times, without losing the original intent.
Think of it as the difference between a model that can answer “how do I write a lexer?” against the one who actually can’t write a complete compilerrun tests against it, find regressions, and fix it – all without a human in the loop. The latter is exactly what the Xiaomi MiMo team is showing you here.
MiMo-V2.5-Pro: Flagship
MiMo-V2.5-Pro is the most capable model of Xiaomi to date, it brings significant improvements over its predecessor, MiMo-V2-Pro, with general agent skills, complex software engineering, and long-term activities.
The main benchmark numbers rival the top closed-source models: SWE-bench Pro 57.2, Claw-Eval 63.8, and τ3-Bench 72.9 — putting it right next to the Claude Opus 4.6 and GPT-5.4 in all tests. V2.5-Pro can support complex, long-horizon tasks that include more than a thousand tool calls, showing significant improvements in the commands that follow within the agent’s context, reliably complying with the subtle requirements embedded in the context and maintaining strong compatibility in all very long scenarios.
One characteristic property that distinguishes the V2.5-Pro from previous models is what the Xiaomi MiMo team calls “harness awareness”: it takes full advantage of the harness’s local ability, manages its memory, and shapes how its core is filled to achieve the ultimate goal. This means that the model does not simply issue instructions to the machine. It is actively developing its work environment to stay on track for all the longest operations.
The three demos of real-world work Xiaomi has published show exactly what “long-horizon agetic capability” means in practice.
Demo 1 – SysY Compiler in Rust: Referring to Peking University’s Compiler Principles course project, this work asks the model to implement a complete SysY compiler in Rust from scratch: lexer, parser, AST, Koopa IR codegen, RISC-V assembly backend, and performance optimization. A reference project usually takes a senior PKU CS student several weeks. The MiMo-V2.5-Pro finished in 4.3 hours for all 672 tool calls, scoring a total of 233/233 against the course’s hidden test suite.
What is remarkable is not only the final result – the composition of the execution. Rather than going through trial and error, the model builds the compiler layer by layer: close the full pipeline first, the proper Koopa IR (110/110), then the RISC-V backend (103/103), then the performance (20/20). The first batch alone passed 137/233 tests, a cold start of 59% which suggests that the build was properly designed before a single test was run. When the rollback step caused a reversal, the model detected a failure, recovered, and moved forward. This is systematic, self-correcting engineering behavior — not pattern-matched code generation.
Demo 2 — Full-Featured Desktop Video Editor: With just a few simple notifications, MiMo-V2.5-Pro has delivered a functional desktop application: multi-track timeline, clip cutting, cross-fading, audio mixing, and export pipeline. The final build is 8,192 lines of code, generated over 1,868 tool calls in 11.5 hours of independent work.
Demo 3 — Analog EDA- FVF-LDO Design: This is a very special demo: a graduate-level analog-circuit EDA project that requires the design and optimization of a complete FVF-LDO (Flipped-Voltage-Follower low-dropout regulator) from scratch on a TSMC 180nm CMOS process. The model had to measure the power transistor, tune the compensation network, and choose the bias voltages so that six metrics stayed within spec at the same time – phase limit, line control, load control, quiescent current, PSRR, and transient response. Fitted with an ngspice simulation loop, in about an hour of closed-loop iteration – calling the simulator, learning waveforms, changing parameters – the model produced a design where every target metric was met, with four key metrics improved by an order of magnitude over their first attempt.
Performance of Signs: Intelligence at the frontier level is only useful if it is economical. In ClawEval, V2.5-Pro is sitting at 64% Pass^3 using only ~70K tokens per trajectory – about 40–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 at comparable skill levels. For developers building agent pipelines, this is about reducing material costs, not just marketing statistics.
MiMo Coding Bench is Xiaomi’s internal test suite designed to test real-world developer activity models within agent frameworks such as Claude Code. It includes repo understanding, project creation, code review, structured artifact generation, programming, SWE, and more. V2.5-Pro is leading the field in this benchmark, and Xiaomi is clearly positioning it as a fallback for frameworks including Claude Code, OpenCode, and Kilo.
MiMo-V2.5: Native Omnimodal in Cost Segmentation
While the V2.5-Pro targets the most demanding horizon agent tasks, the MiMo-V2.5 is a big step forward in the agent’s power and multipath understanding. With native visual and audio understanding, MiMo-V2.5 seamlessly reasons across all modes, surpasses MiMo-V2-Pro in agent performance, and supports up to one million context tokens.
The model is built with vision and action integrated from the ground up. MiMo-V2.5 is trained from the ground up to see, feel, and act on what it sees, resulting in a single model that understands everything and makes things happen. This is structurally important – previous multimodal models tend to block vision over the core of the text, creating energy gaps at the border of visual action.
On the coding side, the value proposition is clear: on the MiMo Coding Bench, the MiMo-V2.5 delivers strong results in daily coding tasks, bridging the gap with boundary models and matching the MiMo-V2.5-Pro at half the cost. For teams that don’t need the extreme long-horizon depth of the V2.5-Pro, this is a compelling performance point.
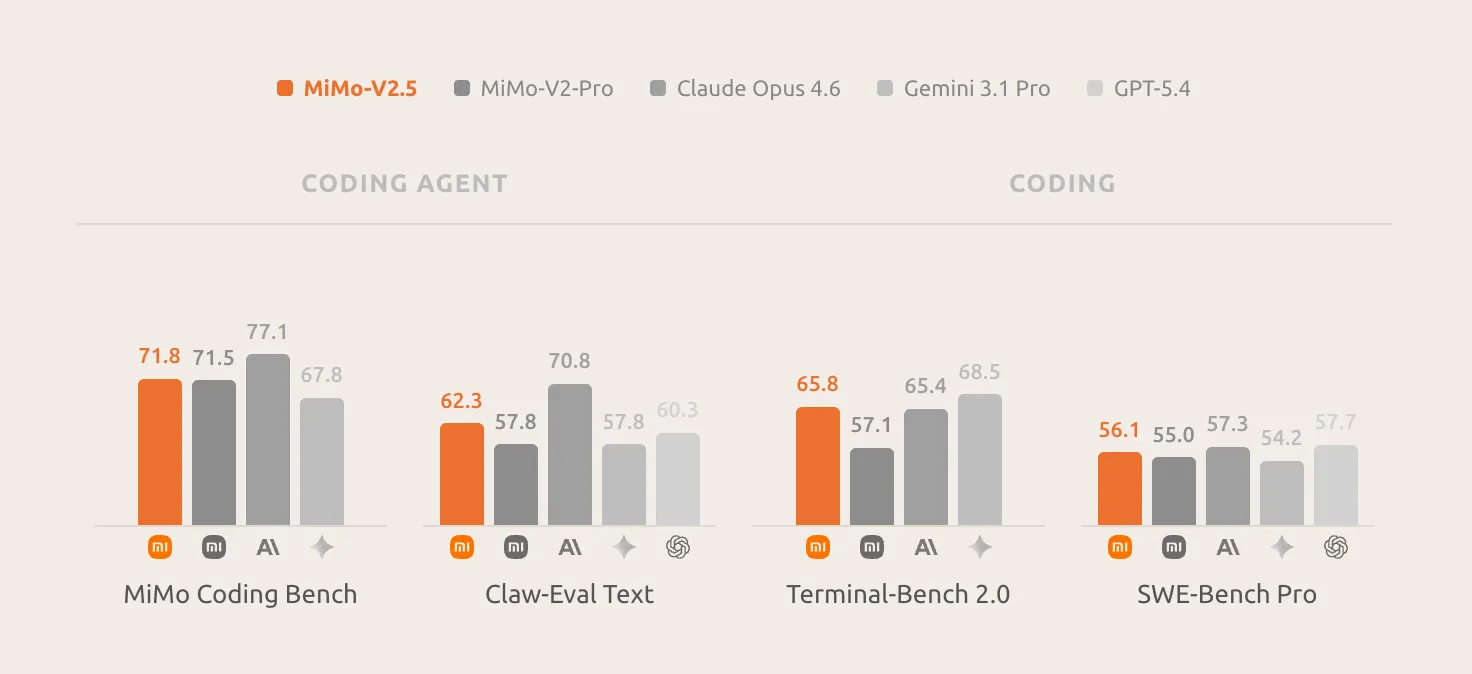
In multimodal benchmarks: MiMo-V2.5 achieves 62.3 in the Claw-Eval standard subset, placing it on the Pareto frontier of efficiency and effectiveness. In the multimodal agent subset, MiMo-V2.5 reaches 23.8 in Claw-Eval Multimodal, which is in line with Claude Sonnet 4.6, leading MiMo-V2-Omni by eight points, and then following Claude Opus 4.6 by one point.
In terms of video, the MiMo-V2.5 scores 87.7 in Video-MME, effectively tied with the Gemini 3 Pro (88.4) and well ahead of the Gemini 3 Flash. Long-term video understanding – location tracking, temporal thinking, visual support for minutes of video – is now at the frontier. In terms of graphics, the MiMo-V2.5 sits at 81.0 on the CharXiv RQ and 77.9 on the MMMU-Pro, closing in on the Gemini 3 Pro.
The price is direct: MiMo-V2.5 works at 1x (1 token = 1 credit), while MiMo-V2.5-Pro works at 2x (1 token = 2 credits). Token Plans no longer charge a multiplier for a 1M token context window – previously it was a typical cost bump for long content agent workloads.
Key Takeaways
- MiMo-V2.5-Pro is similar to the closed-source models of the border in key agent benchmarks (SWE-bench Pro 57.2, Claw-Eval 63.8, τ3-Bench 72.9), while using 40–60% fewer tokens per trajectory than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4.
- Long-horizon independence is real and measurable — V2.5-Pro automatically builds a complete SysY compiler in Rust (233/233 tests, 672 tool calls, 4.3 hours) and a full-featured desktop video editor (8,192 lines of code, 1,868 calls, 11.5 hours).
- MiMo-V2.5 is a universal creation — trained from scratch to see, hear, and perform across modes with a native 1M token context window, such as Claude Sonnet 4.6 on Claw-Eval Multimodal and nearly tying Gemini 3 Pro on Video-MME (87.7 vs. 88.4).
- High-level code performance in the cost segment — On the MiMo Code Bench, the MiMo-V2.5 matches the MiMo-V2.5-Pro for everyday coding tasks at 1x token rates, making it a realistic choice for most production agent pipelines.
- Both models are like that it’s already compatible with popular frameworks like Claude Code, OpenCode, and Kilo – giving AI devs an accessible, testable, self-hosted path to frontier-level AI.
Check it out Technical specifications MiMo-V2.5again Technical specifications MiMo-V2.5-Pro. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.?Connect with us
The post Xiaomi Releases MiMo-V2.5-Pro and MiMo-V2.5: Matching Frontier Model Benchmarks at Significantly Lower Token Costs appeared first on MarkTechPost.



