
Major linguistic models (LLMs) are not really big computer brains. Instead, they are large vector spaces in which the probability of tokens occurring in a particular order is encoded. Billions of parameters, N times the number of bits per parameter, equals the N-billion bits of storage required for a full model. Since increasing the number of parameters makes models appear smarter, the main effort to reduce the storage we need has been in reducing the size of the parameters themselves.
Vector quantization (VQ) is a new technique that can compress the vectors calculated during projection to occupy less space without significant data loss. A recently published Google preprint paper on TurboQuant covers an LLM-oriented VQ algorithm that is said to provide a compression rate of up to 6x with no negative impact on processing times.
Tokens are not written directly into the vector space, but their associated key value is, and one token for each indexing process creates the need for a key-value cache (KV), the size of which scales with the size of the model. So by compressing the KV cache using VQ, it will reduce its size and correspondingly speed up the lookup due to the smaller memory size. One catch here is that VQ is due to the nature of quantization some accuracy will be lost. The trick here is to use VQ in such a way that it doesn’t affect this accuracy significantly.
Other features to consider for the TurboQuant algorithm were fast calculations to meet real-time needs, as well as compatibility with so-called ‘AI accelerator’ hardware.
Key Value Store
The basic way to look at the KV repository in LLMs is that it stores the results of previous ideation cycles. An in-depth explanation for example can be found in this article by Sebastian Raschka. In the case of generating a three-word phrase starting with the word ‘Time’, we can see the following repeated figures:
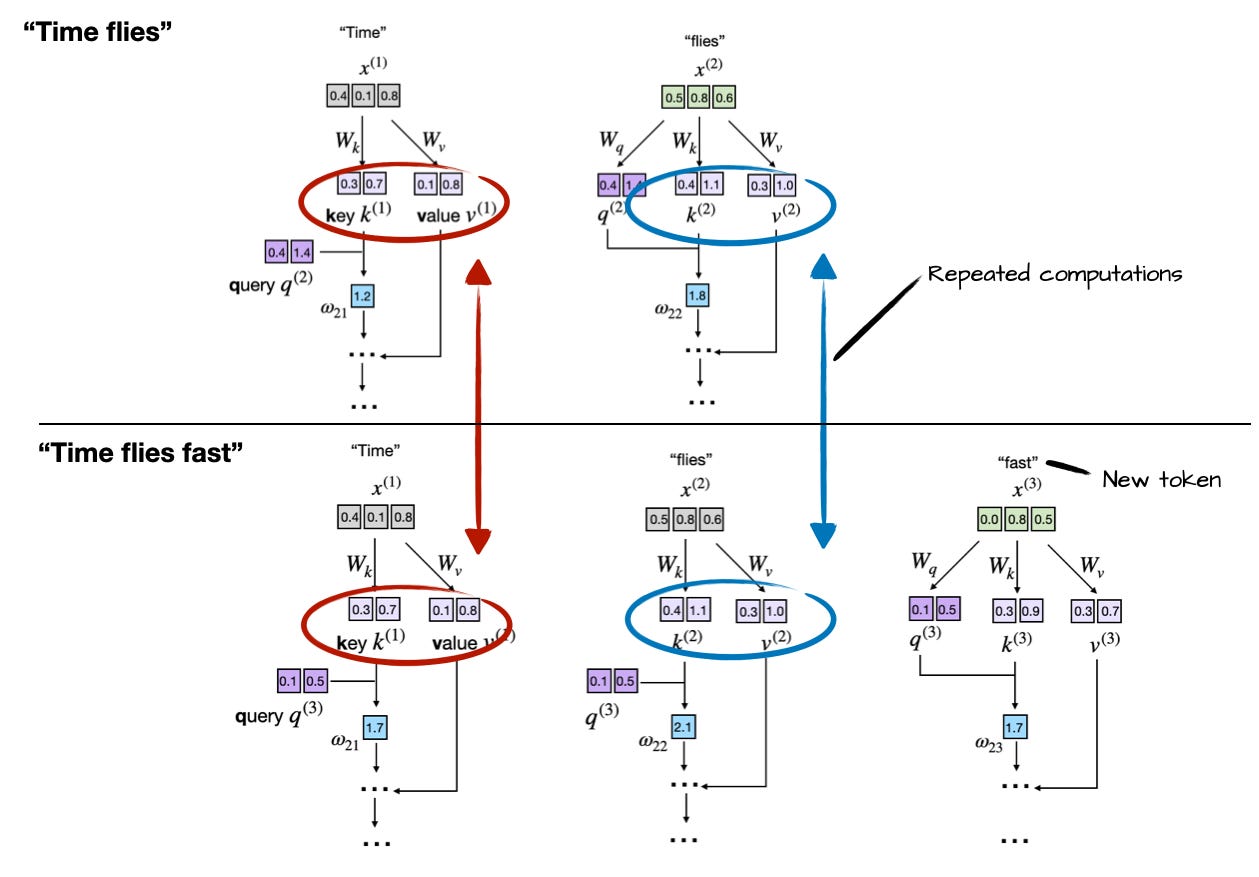
If you think that the assumption is too expensive statistically, you really want to keep these calculated values. This provides a significant improvement in performance and a very low CPU load, but because there is no such thing as a free lunch the catch here is that memory usage increases rapidly.
Accordingly, we now have a large memory cache to manage, and memory management processes to make sure that the KV cache does not exceed its allocated memory:
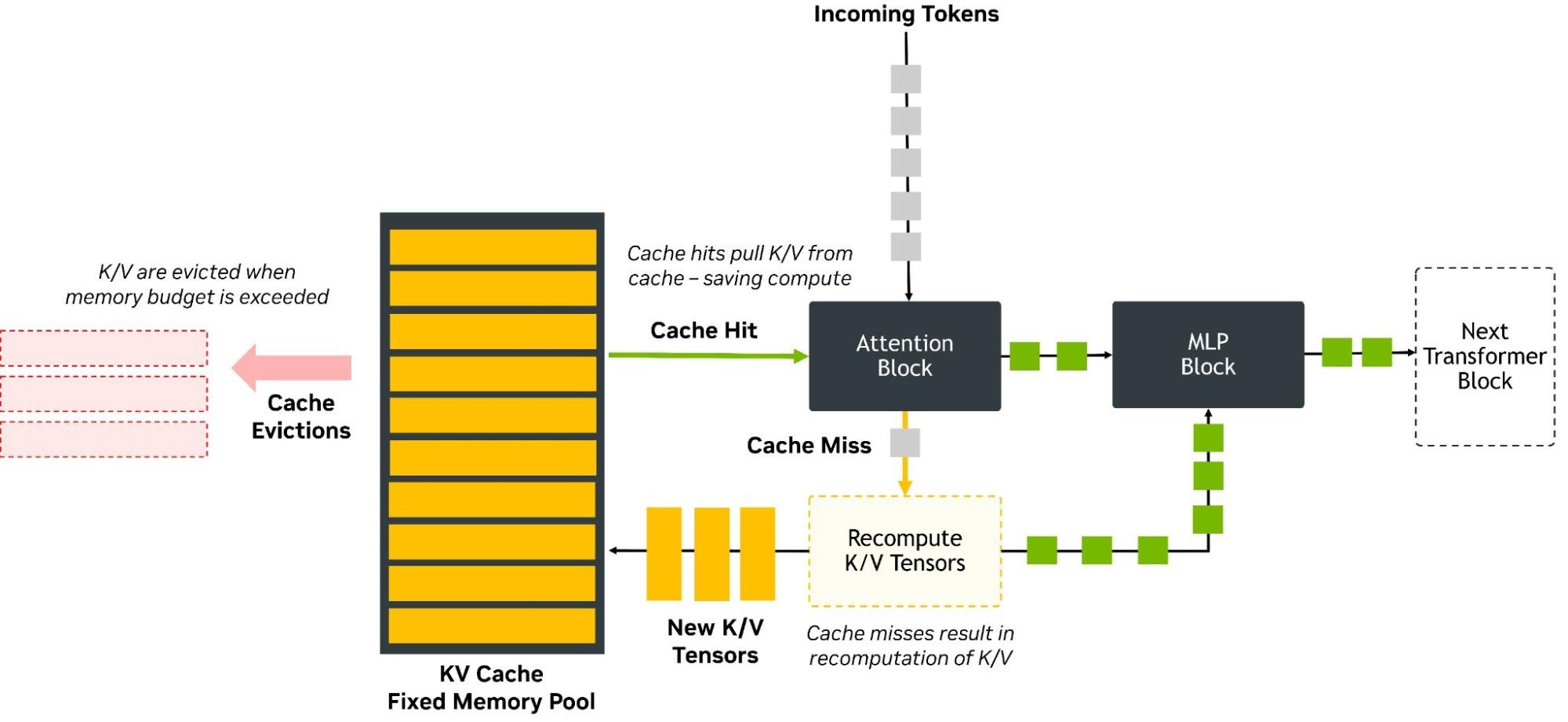
As revealed in the December 2025 NVIDIA Developer article, KV cache implementation has been a topic for a while, with the article in question covering NVFP4. This is a VQ method that reduces the precision of the KV cache from 16-bit to 4-bit (FP4). At that time production systems were already using 8-bit quantization, and using floating point format (FP8).
The additional cost here is that FP4 has to be downgraded back to FP8, which would appear to be an implementation detail in the current version. Compared to FP8 benchmarks, FP4 reduces latency by up to 3 times and halves the required memory, while accuracy suffers less than 1% compared to FP8 due to benchmark error.
Accuracy here is important as it enters the next step of auto-completion where the LLM probability vector space is re-scanned to find the statistically most likely trace token. KV cache compression is therefore always a trade-off between memory usage and accuracy. In short, the same problems apply as with all applications of quantization-based compression, including the unfortunate absence of any free lunch.
Turbo Quantization
So what magic did the intrepid Google engineers conjure up to improve on NVIDIA’s NVFP4 approach? The key is how the estimation is done, as it is not a simple matter of truncating or discarding the data, combining the nearest available value. Instead a series of steps is used that seeks to reduce the quantization error, which in the case of TurboQuant is (confusingly) an algorithm called PolarQuant followed by a QJL (quantized Johnson-Lindenstrauss) algorithm.
To the chagrin of the untalented/mathematics literate among us, Google didn’t just give us a clear vision like that of NVFP4 that even us software developers and other lay people can understand. In the NVIDIA format we can see that it takes the form of one sign bit, two exponents and one mantissa (E2M1), and an average of FP8 distributed per block with 16 values.
One step in which TurboQuant seems to be different is the PolarQuant algorithm, which uses the transformation of polar coordinates in vectors, following which normalization may be exceeded.
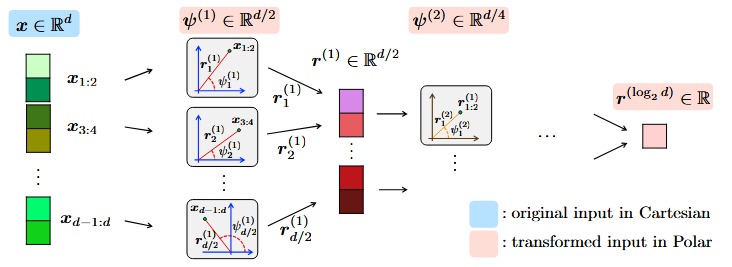
This polar transformation is preceded by the use of a random projection matrix as a kind of precondition that will affect the posterior normal distribution, with the proof and the full algorithm provided in the PolarQuant arXiv paper for those who wish more details.
Of note is that PolarQuant uses the Johnson-Lindenstrauss lemma, which Google researchers used as the basis for a JL-based transformation called QJL. From reading the blog post it is not immediately clear whether QJL is directly integrated with PolarQuant or an additional step, due to a confusing message on Google’s end. From the measurement results it seems that QJL is a further step.
What we do know is that the storage format that TurboQuant saves is a three-bit value, which is logically about 1 bit smaller than NVFP4, or a smaller KV cache of about 25% of the same amount of data.
Judging Rightly
The benchmark comparison data in Google’s blog post and related papers do not provide a direct comparison to NVFP4, and several of the output numbers are inconsistent, or not mentioned. Take the claim of ‘at least 6x smaller memory size’, for example. The blog post doesn’t make it clear what this is related to, while it gives a TurboQuant 4-bit number for an 8x performance increase compared to FP32.
Although with some digging and searching of the available data it may be possible to find some real performance information in the provided files, it is rather worrying how obscure Google’s messaging is kept. Not to mention the lack of direct measurement against potential major competitors in the space.
It is quite true that VQ is a LLM KV cache compression object, as we have seen, and NVIDIA’s ‘accelerator cards’ provide hardware acceleration of this feature, so this is the fact that TurboQuant has to compete with. Based on the few clear facts we have it doesn’t appear to be quite the revolution the hype machine has made it out to be, which may just be a bump over NVFP4 that NVIDIA will likely repeat in its next quantized format.
It will be very interesting to see how this plays out once TurboQuant gets out of the laboratory and into the wider world and we start seeing independent calibrations.
: How does the movie deal with Michael Jackson’s legacy?")


